
Indicizzare e ricercare i blob di Azure Storage
Nel grosso ecosistema dei servizi di Microsoft Azure, lo storage č quello piů importante e rappresenta le basi di molti altri servizi. In particolare, i blob ci permettono di memorizzare terabyte di file in maniera del tutto gestita, sicura e performante, il tutto attraverso operazioni REST.
Dal punto di vista delle prestazioni, caricare o leggere un file sapendone l'URI completo ci garantisce velocitŕ, lasciando a noi quindi il compito di memorizzare in un database separato l'associazione del URI ad altre informazioni che permettano alle logiche applicative e all'utente di trovarlo facilmente. I blob, infatti, soffrono di scarse prestazioni nel momento in cui decidiamo di enumerare la lista dei file alla ricerca di uno con un determinato nome.
Per non dover affiancare un database, di recente č stata introdotta la possibilitŕ di associare dei tag ai blob stessi. Si trattano di coppie chiave/valore che ci permettono di associare stringhe. Diversamente dai metadata, giŕ disponibili, questi tag vengono immediatamente indicizzati, permettendoci di fare ricerche molto velocemente.
Per dare un primo sguardo a questa funzionalitŕ possiamo usare direttamente il portale che, posizionandoci sulle proprietŕ di un file esistente o in fase di upload, ci permette di impostare questi tag.
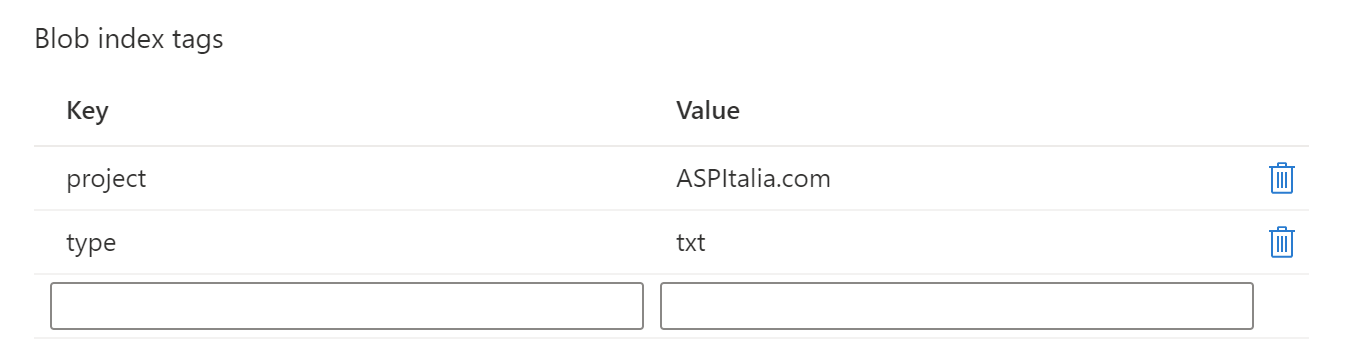
Possiamo inserire fino ad un massimo di 10 chiavi, con una serie di vincoli su dimensioni e caratteri, compreso il fatto che le stringhe sono case sensitive. Possiamo impostare questi tag anche attraverso le API .NET.
var tags = new Dictionary<string, string>
{
{ "project", "ASPItalia.com" },
{ "type", "txt" },
};
await myBlob.SetTagsAsync(tags);L'indicizzazione avviene immediatamente permettendoci poi di ricercare il file, da portale o tramite API.
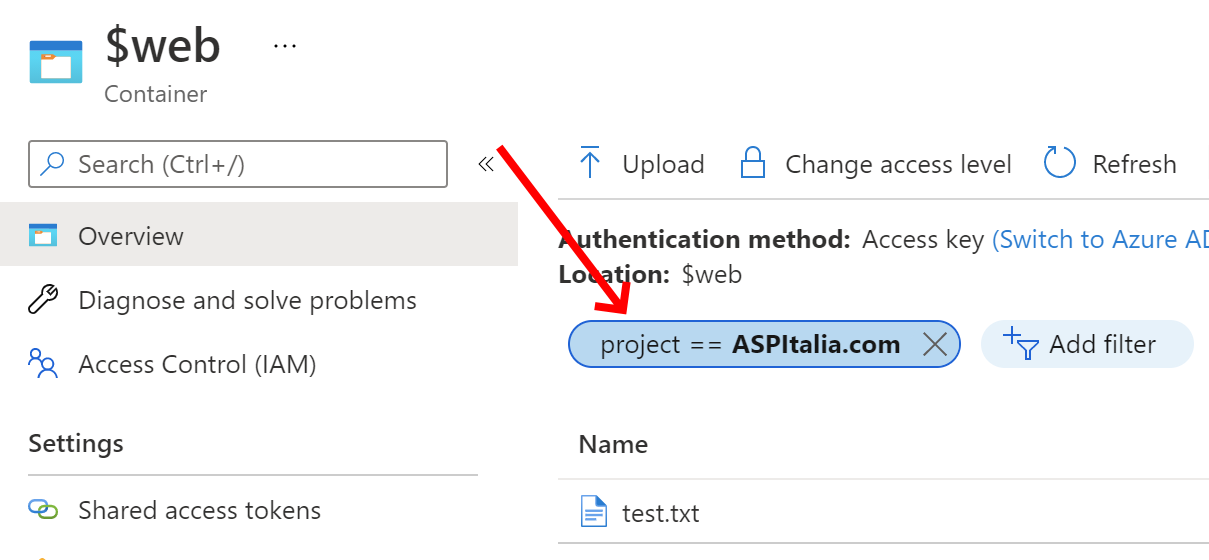
Il corrispettivo con le API .NET č visibile nell'esempio seguente.
var query = "'project' = 'ASPItalia.com'";
await foreach (TaggedBlobItem taggedBlobItem in serviceClient.FindBlobsByTagsAsync(query))
{
Console.WriteLine(taggedBlobItem.Uri);
}La ricerca non si limita al solo operatore di uguaglianza, ma anche quelli di comparazione oltre che a quello logico AND, consentendoci anche di fare ricerche parziali.
Un ultimo aspetto interessante č rappresentato dal fatto che possiamo usare gli indici anche nel lifecycle management per automatizzare processi come lo spostamento e la cancellazione di file. Per conoscere tutti gli aspetti e limiti, rimandiamo comunque alla documentazione ufficiale:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-manage-find-blobs
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Path addizionali per gli asset in ASP.NET Core MVC
Ottimizzare le performance delle collection con le classi FrozenSet e FrozenDictionary
Esporre i propri servizi applicativi con Semantic Kernel e ASP.NET Web API
Migliorare la sicurezza dei prompt con Azure AI Studio
Migliorare l'organizzazione delle risorse con Azure Policy
Autenticarsi in modo sicuro su Azure tramite GitHub Actions
Definire stili a livello di libreria in Angular
Utilizzare Container Queries nominali
Paginare i risultati con QuickGrid in Blazor
Ottimizzare le pull con Artifact Cache di Azure Container Registry
Garantire la provenienza e l'integrità degli artefatti prodotti su GitHub
Referenziare un @layer più alto in CSS



