
Eseguire attivitŕ basate su eventi con Azure Container Jobs
Nel precedente script #263 abbiamo visto come Azure Container Jobs ci offre la possibilitŕ di eseguire job containerizzati che operano per una durata definita e terminano quando il compito č completato. Questi jobs possono essere eseguiti manualmente oppure ad intervalli regolari, ma č interessante poterli avviare anche tramite trigger.
I trigger si basano sempre sulle regole di scaler di KEDA e, a differenza dell'app, dove una o piů istanze vengono attivate in base alle regole per processare piů eventi in sequenza o in bulk, applicati ai job causano la creazione di un'istanza per ogni trigger, e risultano quindi l'ideale per operazioni lunghe che necessitano di istanze specifiche di elaborazione.
In fase di creazione di un job dal portale, quindi, se selezioniamo Event ci viene chiesto quali regole dello scaler applicare, come per le app.
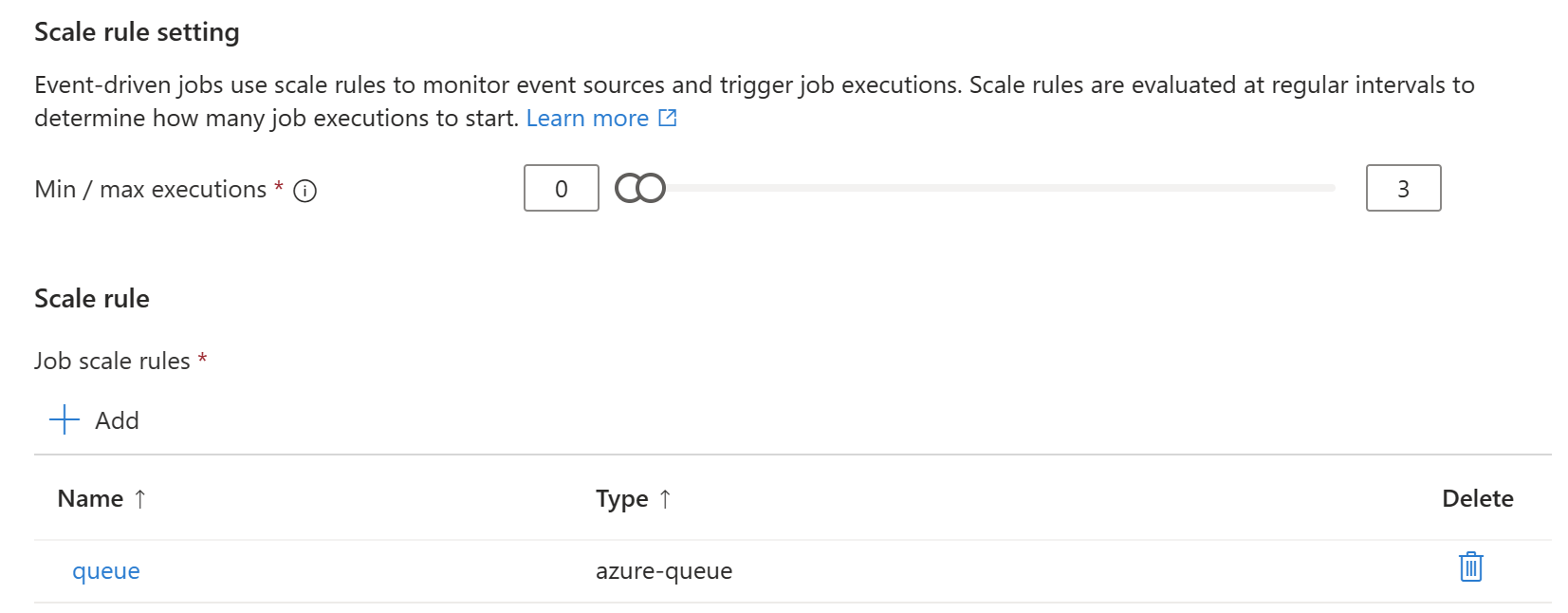
Poiché gli eventi possono essere molteplici, possiamo restringere il numero minimo e massimo di istanze da prendere in carico. Nello scaler impostiamo come al solito le tipologie e i metadati, secondo quanto previsto dalla documentazione https://keda.sh/docs/scalers/.
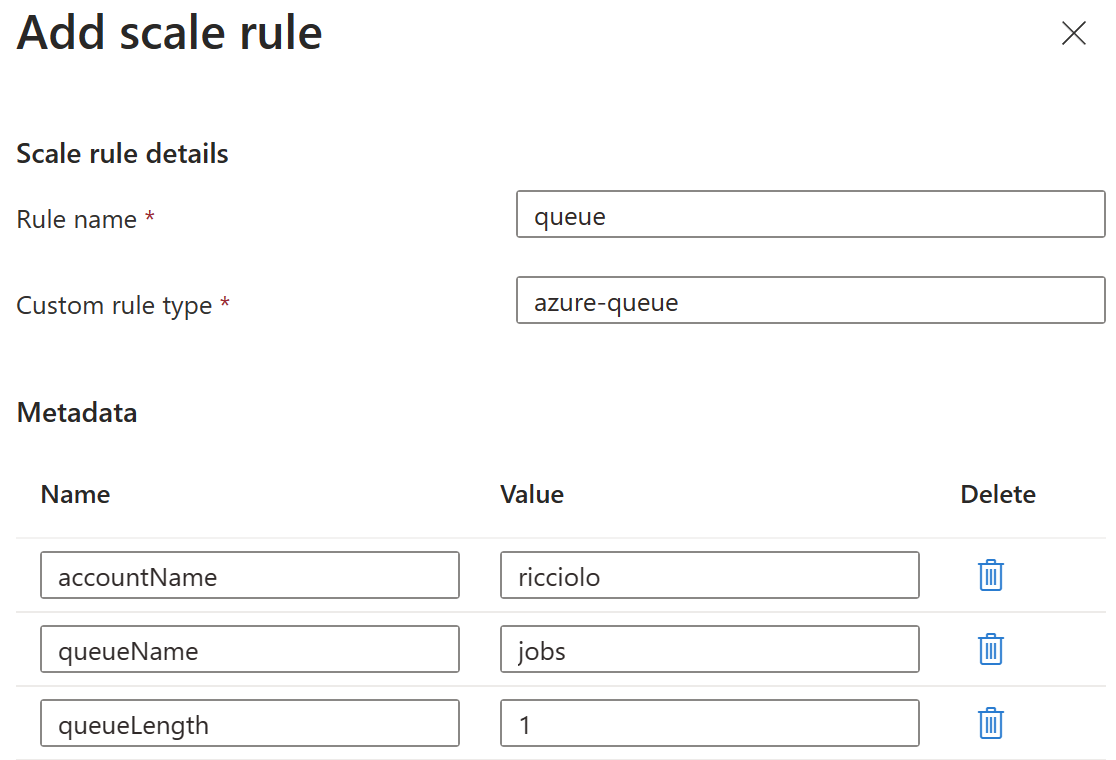
Nell'esempio impostiamo una regola basata sulle code di Azure Storage. Purtroppo, l'interfaccia non permette ancora di impostare la parte dedicata all'autenticazione e all'utilizzo dello scaler, perciň dobbiamo ricorrere ad Azure CLI per impostare la secret da usare per la stringa di connessione.
az containerapp job update -n ricciolo2 -g ricciolo --scale-rule-auth "connection=azurewebjobsstorage" --scale-rule-type "azure-queue" --scale-rule-name queue --scale-rule-metadata "accountName=ricciolo" "queueName=jobs" "queueLength=1"
Creato e impostate le regole del job, lo scaler monitora ogni 20 secondi (modificabile tramite Azure CLI) lo stato della coda e verifica la presenza di messaggi. In base al numero crea le istanze necessarie e, poiché abbiamo impostato un queueLength a 1, in caso di tre messaggi creerŕ 3 istanze. In caso di 5 messaggi ne creerŕ comunque 3 per via dei limiti che abbiamo messo. A questo punto č compito del job togliere i messaggi (peek/lock oppure receive/delete) dalla coda affinché lo scaler non li veda al controllo successivo, pena la creazione di altre istanze.
In questo modo i job partono, eventualmente considerando le repliche, che non rientrano nel conto dell'istanze, e possono eseguire con tutto il tempo necessario l'attivitŕ. Non č previsto un modo per indicare per quale scopo specifico č prevista quell'istanza; perciň, č compito del container recuperare il lavoro da effettuare. Nel caso di una coda, il semplice prelievo del messaggio disponibile č sufficiente per distribuire i lavori.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Gestire eccezioni nei plugin di Semantic Kernel in ASP.NET Core Web API
Eseguire query per recuperare il padre di un record che sfrutta il tipo HierarchyID in Entity Framework
Introduzione alle Container Queries
Creare una libreria CSS universale: i bottoni
Bloccare l'esecuzione di un pod in mancanza di un'artifact attestation di GitHub
Rendere i propri workflow e le GitHub Action utilizzate più sicure
Utilizzare DeepSeek R1 con Azure AI
Utilizzare Hybrid Cache in .NET 9
Applicare un filtro per recuperare alcune issue di GitHub
Utilizzare Azure AI Studio per testare i modelli AI
Esporre i propri servizi applicativi con Semantic Kernel e ASP.NET Web API
Utilizzare il metodo IntersectBy per eseguire l'intersection di due liste



