
Potenziare Azure AI Search con la ricerca vettoriale
Azure AI Search (precedentemente chiamato Cognitive Search) č un servizio di ricerca di Microsoft Azure che ci permette di creare esperienze di ricerca ricche e personalizzate per i nostri utenti. Puň indicizzare dati strutturati e testo, rendendo le informazioni facilmente ricercabili. I suoi vantaggi includono scalabilitŕ, integrazione con altri servizi Azure, e funzionalitŕ avanzate come ricerca full-text, filtraggio, ordinamento e suggerimenti. Il tutto viene esposto tramite API REST e SDK per i rispettivi linguaggi in pieno stile Microsoft Azure.
Di recente č stata aggiunta la possibilitŕ di indicizzare, oltre a testo e numeri, anche array di numeri aprendo le porte alla ricerca vettoriale, molto utile nell'ambito dell'intelligenza artificiale. In questo campo, infatti, testi, suoni e immagini possono essere rappresentati tramite vettore secondo un motore di embedding, come per esempio ADA, BERT, Word2vect, GloVe, che ne determina i valori. Contenuti simili o affini, a seconda del motore utilizzato, restituiscono vettori, cioč un punto multidimensionale la cui distanza č inferiore rispetto ad altri contenuti meno rilevanti.
In Azure AI Search possiamo quindi popolare i documenti con titoli, riferimento alla fonte, categorie, ecc, ma anche aggiungere uno o piů campi di tipo collezione di single (32bit a virgola mobile) per effettuare una ricerca vettoriale oppure ibrida (ricerca full text), con o senza semantica.
Per sfruttare questa funzionalitŕ dobbiamo prima di tutto creare un indice o modificarne uno giŕ esistente, come mostrato nella figura seguente.
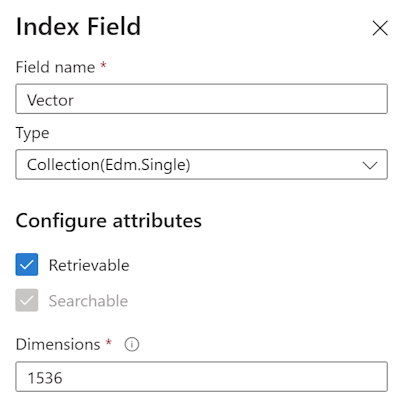
Per ogni campo va abbinato un profilo di ricerca che, se non ancora creato, va preparato per indicare le modalitŕ di ricerca del vettore. Azure AI Search supporta due algoritmi:
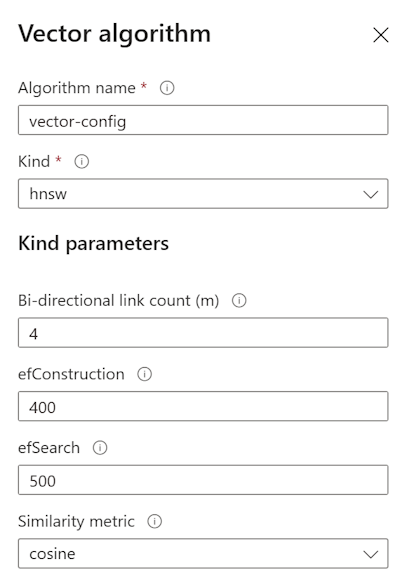
- Hierarchical Navigable Small World (HNSW): algoritmo veloce e scalabile che richiede di mantenere tutti gli indici di memoria consumando la quota di spazio dell'indice;
- Exhaustive K-nearest neighbors (KNN): calcola la distanza scorrendo tutti i punti e calcolando la distanza. L'algoritmo č piů lento, adatto per piccoli dataset, ma č piů preciso.
Nella figura seguente utilizziamo HNSW con i valori standard, il quale permette comunque di effettuare una ricerca esaustiva, se necessario.
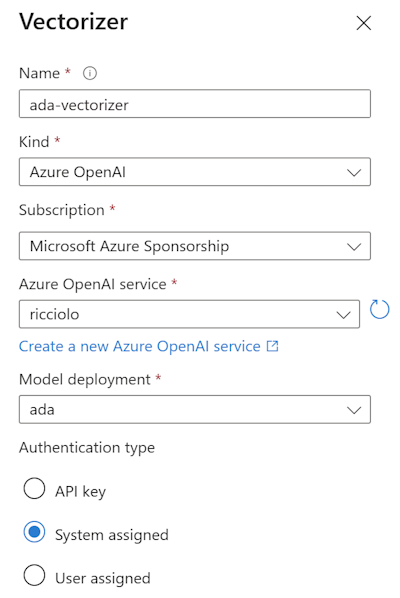
Tornando alla configurazione del profile di ricerca, possiamo eventualmente impostare un motore di vettorizzazione. Questo valore č facoltativo e dipende da come vogliamo calcolare i vettori. Possiamo, per esempio, utilizzare Azure OpenAI e il motore ADA per gli embedding sul testo, come mostrato di seguito.
A questo punto, come previsto da Azure AI Search, possiamo popolare l'indice con un approccio pull, sfruttando i data source giŕ previsti e di conseguenza sfruttando il vectorizer scelto, o con un approccio push, usando le API (o SDK) per inviare i contenuti, come mostrato nell'esempio seguente di chiamata REST.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"vector": [
-0.024740582332015038,
...
],
"@search.action": "upload"
}
]
}Popolato il nostro indice e sfruttando il Search Explorer dovremmo trovare i nostri documenti.
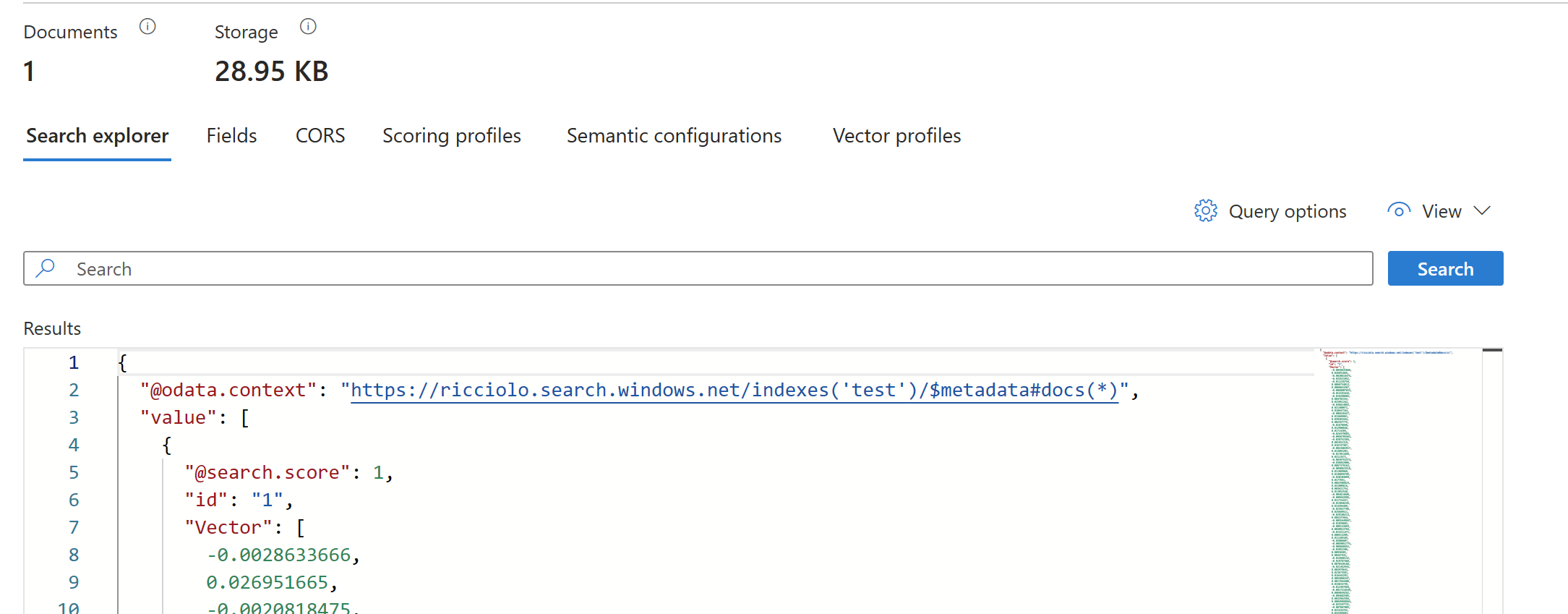
Per effettuare una ricerca possiamo ancora una volta usare SDK o le REST API, come nell'esempio seguente dove richiediamo i 5 documenti piů vicini.
POST https://my-search-service.search.windows.net/indexes/my-index/docs/search?api-version=2023-11-01 Content-Type: application/json api-key: {{admin-api-key}} { "vector": { "value": [ -0.009154141, 0.018708462, . . . -0.02178128, -0.00086512347 ], "fields": "Vector", "k": 5 }, "select": "id" }
Otteniamo cosě la lista degli id e delle eventuali altre informazioni che abbiamo richiesto, utile nel caso in cui stiamo implementando il Retrieval-Augmented Generation (RAG).
Dal punto di vista dei costi ciň che va tenuto conto č l'ingrandirsi dello spazio dell'indice (a seconda dell'algoritmo di ricerca) e dei documenti che ora contengono i vettori.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Esporre un server MCP con Azure API Management
Usare la parola chiave field per semplificare la scrittura di proprietà in C#
Ospitare n8n su Azure App Service
Proteggere l'endpoint dell'agente A2A delle Logic App
Integrare SQL Server in un progetto .NET Aspire
Creare comandi nella dashboard .NET Aspire
Ridimensionamento automatico input tramite CSS
Impostare automaticamente l'altezza del font tramite CSS
Recuperare gli audit log in Azure DevOps
Gestione delle issue type con GitHub
Utilizzare Intersect e Except per filtrare set di dati in TSql
Migrare applicazioni legacy nel cloud con Azure App Service Managed Instance

