
Utilizzare Azure Cosmos DB con i vettori
I vettori sono sostanzialmente degli array di numeri che sono diventati molto utili nella negli embedding. Sono rappresentazioni matematiche in uno spazio ad alta dimensione, utili per descrivere dati complessi come parole, frasi, immagini o suoni. Sono fondamentali nell'IA per ricerche semantiche, raccomandazioni e rilevamento di anomalie, poiché catturano le caratteristiche essenziali dei dati in un formato che le macchine possono elaborare efficacemente.
Quando vogliamo effettuare una ricerca, oltre a campi di filtro con ricerca esatta o con ricerca testuale, tramite gli embedding possiamo fare ricerche di concetto e filtrarle/ordinarle secondo criteri di vicinanza. In Azure possiamo giŕ usare Azure AI Search per effettuare questo lavoro, ma in alternativa č stata introdotta la possibilitŕ di sfruttare questa caratteristica anche con Cosmos DB.
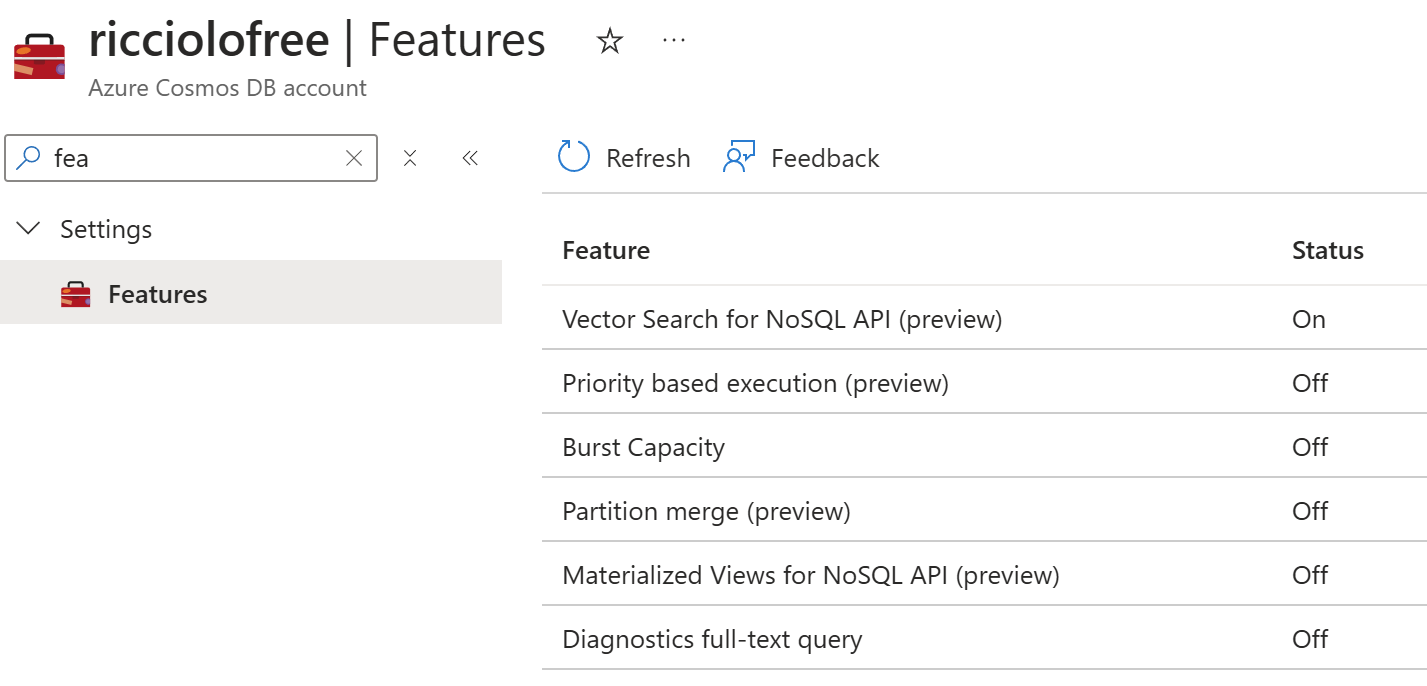
Per usufruire di questa caratteristica dobbiamo prima di tutto abilitare il supporto andando nella sezione Features del nostro account Cosmos DB ed abilitare la voce Vector Search for NoSQL API.
A questo punto dobbiamo creare un nuovo container, perché non possiamo applicare la ricerca vettoriale su container giŕ esistenti. In fase di creazione (non piů modificabile poi), dobbiamo istruire il motore in quali path andremo a salvare dei vettori, la tipologia, la dimensione e la funzione di calcolo della distanza. Nell'esempio seguente nel percorso /vector memorizziamo un embedding ADA di 1536 utilizzando la funzione di coseno, quella piů comunemente usata.

Contestualmente alla creazione dobbiamo anche specificare i criteri di indicizzazione da adottare insieme agli altri, che normalmente troviamo nella indexing policy.
Abbiamo a disposizione tre tipologie di indicizzazione:
- flat: memorizza il vettore cosě com'č, fino ad una dimensione massima di 505. E' il metodo piů preciso, ma anche il piů lento nella ricerca;
- quantizedFlat: comprime il vettore di dimensione massima di 4096. E' un buon compromesso, perché rinuncia ad un po' di precisione, restando sempre lento visto che effettua una ricerca lineare come nel caso del flat. La documentazione parla di buone prestazioni fino a 100 mila vettori;
- diskANN: definisce un indice separato che effettua una ricerca piů approssimata, ma garantisce ottime prestazioni.
Definiziamo quindi l'indice per il nostro vettore utilizzando la compressione, come nell'esempio.

A questo punto possiamo popolare il database e provare ad effettuare una query usando la funzione VectorDistance. A seconda della funziona usata restituisce un numero che, nel caso del cosino, restituisce un punteggio da 0 a 1 a seconda della similaritŕ di due vettori.
SELECT c.title, VectorDistance(c.contentVector, [1,2,3, ...]) AS score FROM c ORDER BY VectorDistance(c.contentVector, [1,2,3, ...])
Grazie a questa funzione possiamo contestualmente effettuare altri filtri e selezionare quali campi vogliamo estrarre. Dal punto di vista del pricing, tutto questo va ad influenzare gli RU necessari per la ricerca e lo spazio dedicato alla memorizzazione degli indici.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Testare l'invio dei messaggi con Event Hubs Data Explorer
Ottimizzare le performance usando Span<T> e il metodo Split
Migliorare l'organizzazione delle risorse con Azure Policy
Utilizzare il nuovo modello GPT-4o con Azure OpenAI
Supportare la sessione affinity di Azure App Service con Application Gateway
Creare una libreria CSS universale: Immagini
Eseguire query per recuperare il padre di un record che sfrutta il tipo HierarchyID in Entity Framework
.NET Aspire per applicazioni distribuite
Eseguire i worklow di GitHub su runner potenziati
Creare agenti facilmente con Azure AI Agent Service
Sfruttare GPT-4o realtime su Azure Open AI per conversazioni vocali
Gestire la cancellazione di una richiesta in streaming da Blazor



